Variable Selection Analysis
Amanda Skarlupka
2019-10-30
Overview
This document will guide you through some data analysis tasks with a focus on performing variable selection. For this exercise, we consider a categorical outcome.
While this is in some sense a stand-alone analysis, I assume that you have worked through the Data Analysis exercise and are familiar with the dataset and all the things we discovered during the cleaning process. We’ll use the same dataset here but focus on a different outcome. Other than that, the way to work through the exercise is like in the Data Analysis exercise, namely by writing/completing the missing code.
Project setup
We need a variety of different packages, which are loaded here. Install as needed. If you use others, load them here.
library('tidyr')
library('dplyr')
library('readr')
library('forcats')
library('ggplot2')
library('knitr')
library('mlr') #for model fitting.## Loading required package: ParamHelpers##
## Attaching package: 'mlr'## The following object is masked from 'package:e1071':
##
## impute## The following object is masked from 'package:caret':
##
## trainData loading and cleaning
We will again use the Norovirus dataset.
#Write code that loads the dataset
#You can of course re-use code you wrote in the other file.
d <- read_csv("norodata.csv")## Parsed with column specification:
## cols(
## .default = col_double(),
## Author = col_character(),
## EpiCurve = col_character(),
## TDComment = col_character(),
## AHComment = col_character(),
## Trans1 = col_character(),
## Trans2 = col_character(),
## Trans2_O = col_character(),
## Trans3 = col_character(),
## Trans3_O = col_character(),
## Vehicle_1 = col_character(),
## Veh1 = col_character(),
## Veh1_D_1 = col_character(),
## Veh2 = col_character(),
## Veh2_D_1 = col_character(),
## Veh3 = col_character(),
## Veh3_D_1 = col_character(),
## PCRSect = col_character(),
## OBYear = col_character(),
## Hemisphere = col_character(),
## season = col_character()
## # ... with 44 more columns
## )## See spec(...) for full column specifications.## Warning: 2 parsing failures.
## row col expected actual file
## 1022 CD a double GGIIb 'norodata.csv'
## 1022 gge a double Sindlesham 'norodata.csv'Looking at the outcome
For this analysis, our main outcome of interest is if an outbreak was caused by the G2.4 strain of norovirus or not, and how other factors might be correlated with that strain.
#write code to take a look at the outcome variable (gg2c4)
d %>%
ggplot(aes(x = gg2c4)) +
geom_histogram(stat = "count")## Warning: Ignoring unknown parameters: binwidth, bins, pad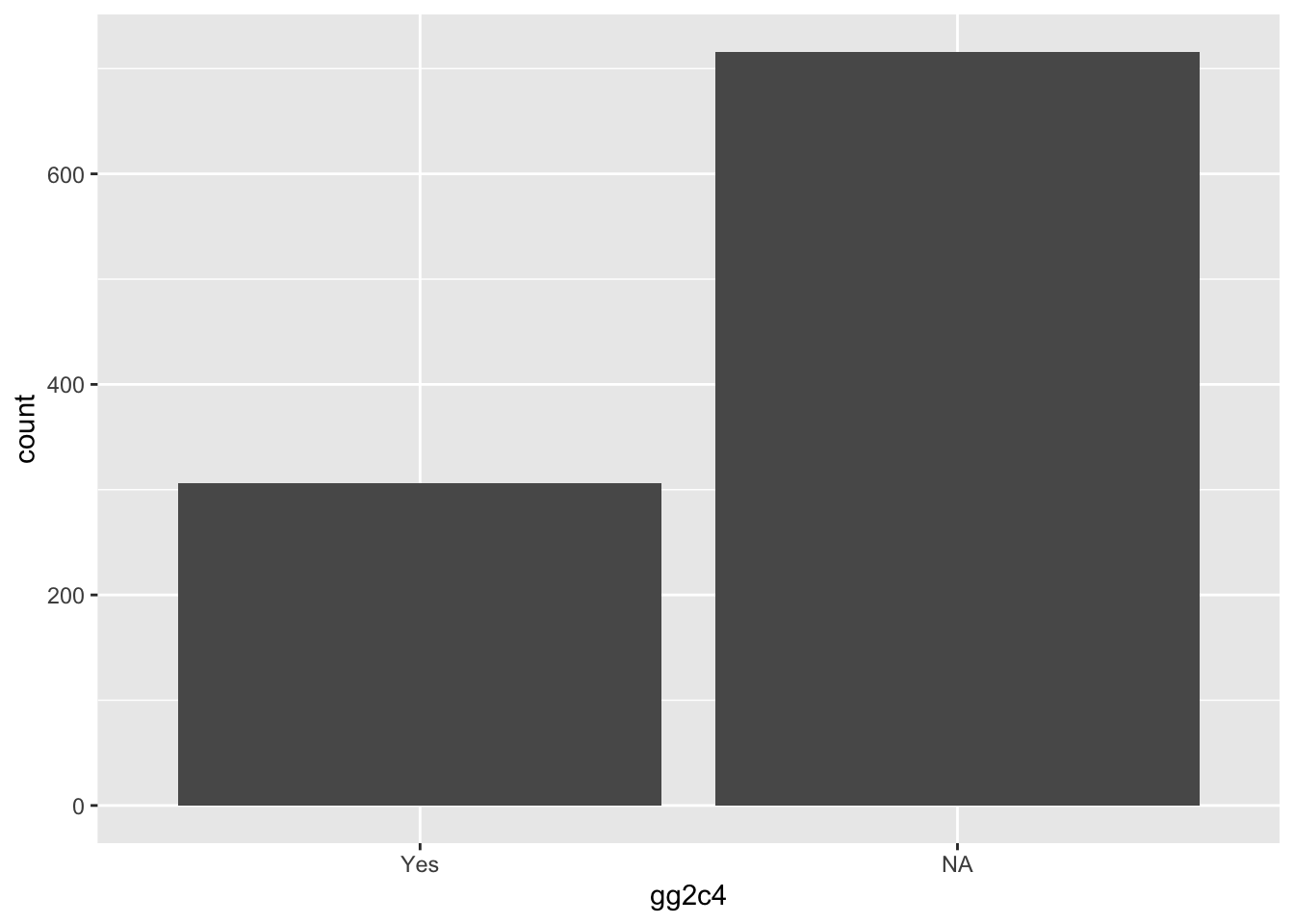 Overall, it looks ok, a decent amout in each category (i.e. no unbalanced data). However, we see an odd coding, there are only 2 types of entries, either “Yes” or "“, i.e. an empty space. The codebook tells us that this is how things were coded, if it was G2.4 it got a”Yes“, if it wasn’t it did get an empty space instead of a”No“. That’s somewhat strange and while the analysis should work, it is better to re-code the empty slots with”No".
Overall, it looks ok, a decent amout in each category (i.e. no unbalanced data). However, we see an odd coding, there are only 2 types of entries, either “Yes” or "“, i.e. an empty space. The codebook tells us that this is how things were coded, if it was G2.4 it got a”Yes“, if it wasn’t it did get an empty space instead of a”No“. That’s somewhat strange and while the analysis should work, it is better to re-code the empty slots with”No".
#write code to change the empty values in gg2c4 to "No"
d$gg2c4[is.na(d$gg2c4)]<-"No"
d$gg2c4 <- as.factor(d$gg2c4)
d$gg2c4## [1] Yes No Yes No Yes No No No Yes No No No No No No No No
## [18] No Yes No Yes Yes Yes Yes Yes Yes Yes Yes Yes Yes Yes Yes Yes No
## [35] Yes Yes Yes No No Yes No No No No No No No No No No Yes
## [52] Yes No No No Yes No No Yes No No No No No Yes No No No
## [69] Yes No No Yes No No No No No No Yes Yes Yes Yes Yes No No
## [86] No No Yes No No No No No Yes Yes Yes No Yes No No No No
## [103] No No Yes Yes No No No No No No No No Yes Yes No No Yes
## [120] Yes Yes No Yes Yes Yes Yes Yes Yes Yes Yes Yes Yes No No No No
## [137] No No No No No No Yes No No No No Yes Yes No No No No
## [154] No No No No No No No No Yes Yes No No Yes No No No No
## [171] No Yes Yes Yes Yes No No No No No No No No Yes No No No
## [188] Yes Yes Yes Yes No Yes Yes No No No Yes Yes Yes No Yes Yes No
## [205] No No No No No No No No No No No No No No No No No
## [222] No No No No No No No No No Yes No No Yes No No No No
## [239] No No No No No No No No Yes No No No No No No No No
## [256] No No No No No No Yes No Yes No No No No No No No No
## [273] No Yes No No No No No Yes No No No Yes No No No No No
## [290] Yes No No No No No No No No No No No No No No No Yes
## [307] No No No No No No Yes No Yes Yes No No No No No No No
## [324] No No No No No No No No No No No Yes Yes No No No No
## [341] No Yes Yes No No Yes No No No No No No Yes Yes Yes Yes No
## [358] No No No No Yes Yes No No No No No No No Yes No Yes No
## [375] Yes No Yes No No No No No No No No No No No No No No
## [392] No Yes Yes Yes Yes No No No Yes Yes No No No Yes No No No
## [409] No No Yes No No No Yes No No No Yes No No No Yes Yes Yes
## [426] No No No No No Yes No No Yes No No Yes Yes No Yes No No
## [443] No No No No No No No No No No Yes No No No No No No
## [460] Yes No No No No No No No No No No No No No No No No
## [477] No No No No Yes No No No No Yes Yes Yes Yes Yes Yes No No
## [494] No No No No No No No No No No No Yes No No No No Yes
## [511] No No No No No Yes No Yes No No No Yes No No No No No
## [528] No No No No No No No No No No Yes Yes No Yes Yes Yes Yes
## [545] Yes Yes Yes Yes No No No No Yes No Yes Yes Yes No No No Yes
## [562] Yes Yes No No No No No No No No No No No No No No No
## [579] No Yes No No No No No No No No No Yes No No No Yes No
## [596] No No No No No No No No No No No No No No No No No
## [613] No No No No No No No No No No No No No No No No No
## [630] No No No No No No No No No No No No No No Yes Yes No
## [647] No No No Yes No Yes No No Yes Yes Yes Yes No Yes Yes No No
## [664] Yes Yes No No No No No Yes No No No No No No No No Yes
## [681] No No Yes No No Yes No No Yes Yes No No No Yes No No No
## [698] No No No No Yes No No No No No Yes No Yes No Yes Yes No
## [715] No No Yes No No No No No No Yes No No No Yes No No No
## [732] Yes Yes Yes No No Yes No Yes Yes No Yes Yes Yes Yes Yes Yes Yes
## [749] Yes Yes Yes No Yes Yes No No No No Yes Yes Yes No Yes Yes Yes
## [766] No Yes No Yes Yes Yes No Yes No No Yes No Yes No No No No
## [783] No No No No No No No No Yes No No Yes Yes Yes No No No
## [800] No No No No No No No No No Yes No No No No No No No
## [817] No No No No No No No No No No No Yes No No Yes Yes No
## [834] No No No Yes No Yes No No No Yes Yes Yes No Yes No Yes Yes
## [851] No Yes Yes No Yes Yes Yes Yes Yes Yes Yes Yes Yes Yes No No No
## [868] No No No No No No No Yes No Yes Yes Yes No Yes No Yes Yes
## [885] Yes Yes No No No No No No No No No No No No No No Yes
## [902] Yes Yes Yes No No No No No No No No No Yes Yes Yes Yes Yes
## [919] No Yes Yes No Yes Yes Yes Yes Yes Yes Yes No Yes No Yes Yes No
## [936] Yes Yes No No Yes No No No No No No No No No No No No
## [953] No No No No No No No No No No Yes No No Yes No No No
## [970] No No No No No No No Yes No Yes Yes Yes Yes Yes Yes Yes Yes
## [987] Yes Yes No No No No No No No No Yes Yes Yes Yes Yes Yes No
## [1004] Yes Yes Yes Yes Yes No No No No No No No Yes No Yes No Yes
## [1021] Yes Yes
## Levels: No YesSelecting predictors
We will pick similar variables as previously, with some adjustments based on what we learned before. Keep the following variables: Action1, CasesAll, Country, Deaths, GG2C4, Hemisphere, Hospitalizations, MeanD1, MeanI1, MedianD1, MedianI1, OBYear, Path1, RiskAll, Season, Setting, Trans1, Vomit.
d <- d %>%
dplyr::select(Action1, CasesAll, Country, Deaths, gg2c4, Hemisphere, Hospitalizations, MeanD1, MeanI1, MedianD1, MedianI1, OBYear, Path1, RiskAll, season, Setting_1, Trans1, Vomit)
dim(d)## [1] 1022 18Cleaning predictors
We’ll likely have to perform similar cleaning steps as before. A difference is that earlier we had to drop about half of the observations because no outcome was available. Here, we have outcome for every outbreak. Thus, there is more data to clean, which - as we will see - introduces a few issues we didn’t have before, since we dropped the troublesome observations early in the process.
Let’s first check for missing values.
# write code that looks at missing values and changes the charcters to factors
d <- as.data.frame(unclass(d))
print(colSums(is.na(d)))## Action1 CasesAll Country Deaths
## 0 7 0 43
## gg2c4 Hemisphere Hospitalizations MeanD1
## 0 0 43 0
## MeanI1 MedianD1 MedianI1 OBYear
## 0 0 0 0
## Path1 RiskAll season Setting_1
## 0 120 67 0
## Trans1 Vomit
## 0 1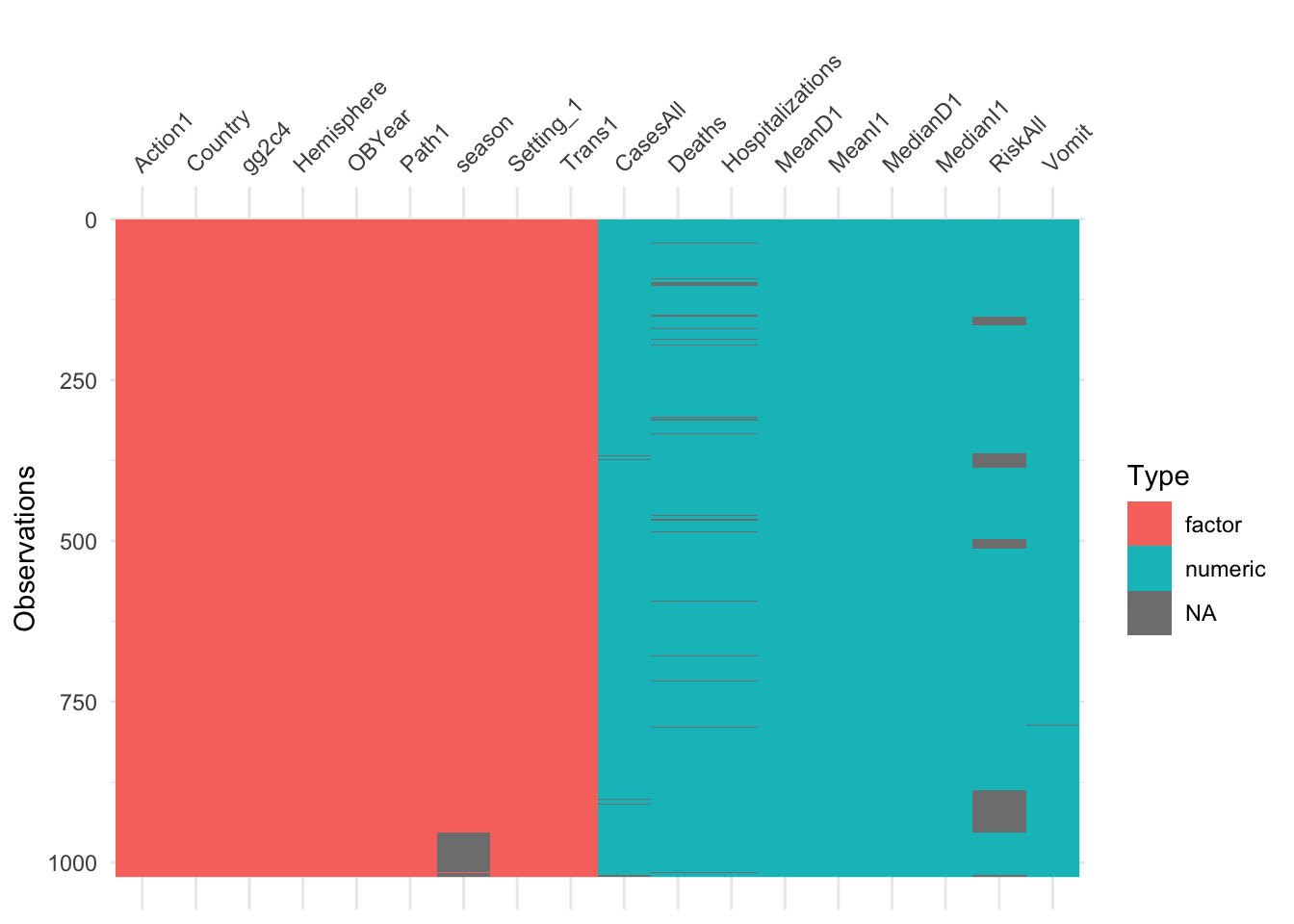
Looks like we have again some missing in Hospitalization and Deaths, and some more in RiskAll. Since the missing is not excessive, and to make our life easier, we’ll drop them for now. Note however the ‘blocks’ of missing values for RiskAll. Given that these outbreaks should be entered fairly randomly into the spreadsheet, it is strange to see the NA show up in such blocks. For a real data analysis, it would be worth looking closer and checking why there is a clustering like that.
# write code to remove any observations with NA
d <- d %>%
filter(is.na(Hospitalizations) == FALSE)
d <- d %>%
filter(is.na(Deaths) == FALSE)
d <- d %>%
filter(is.na(RiskAll) == FALSE)
visdat::vis_dat(d)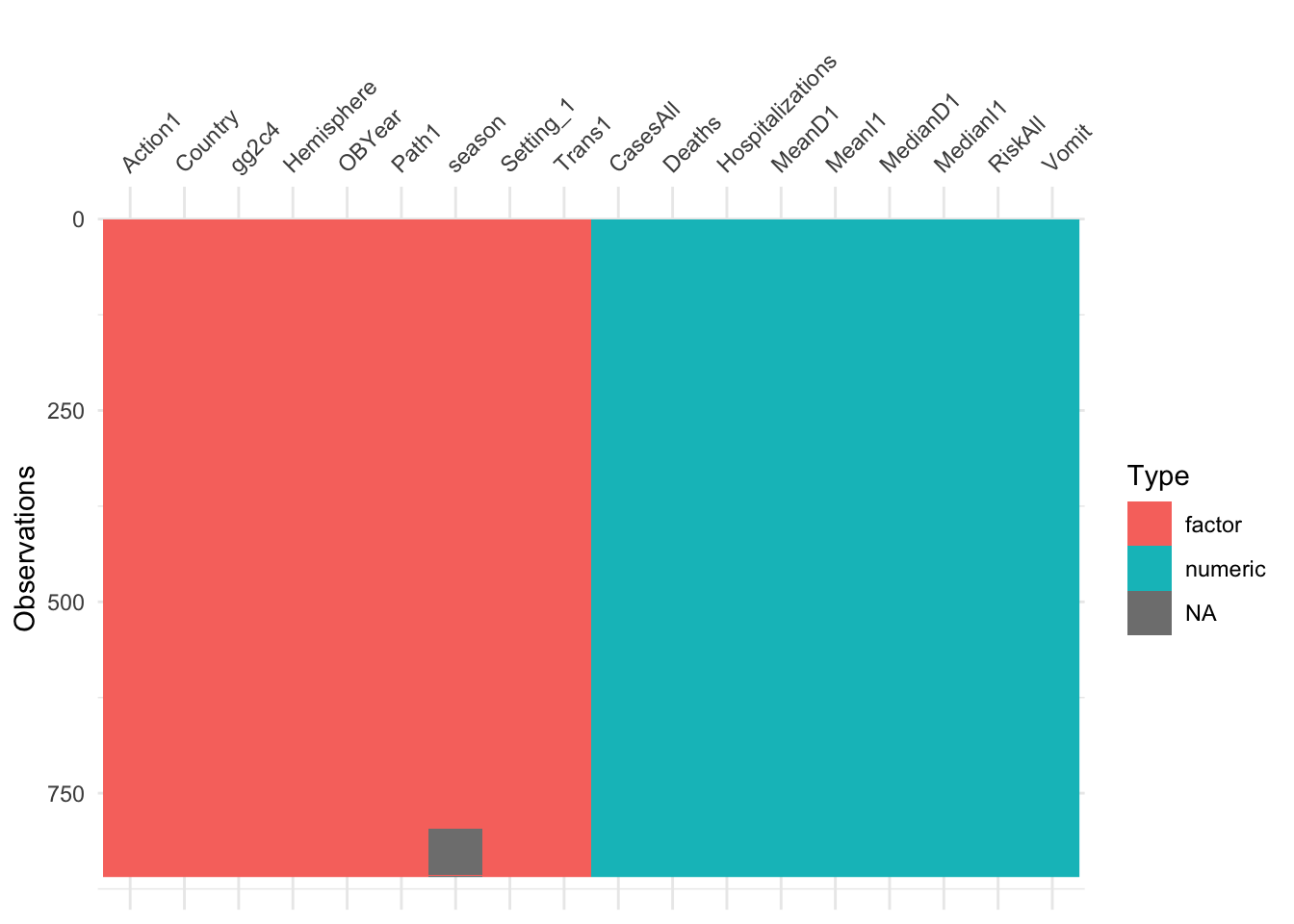
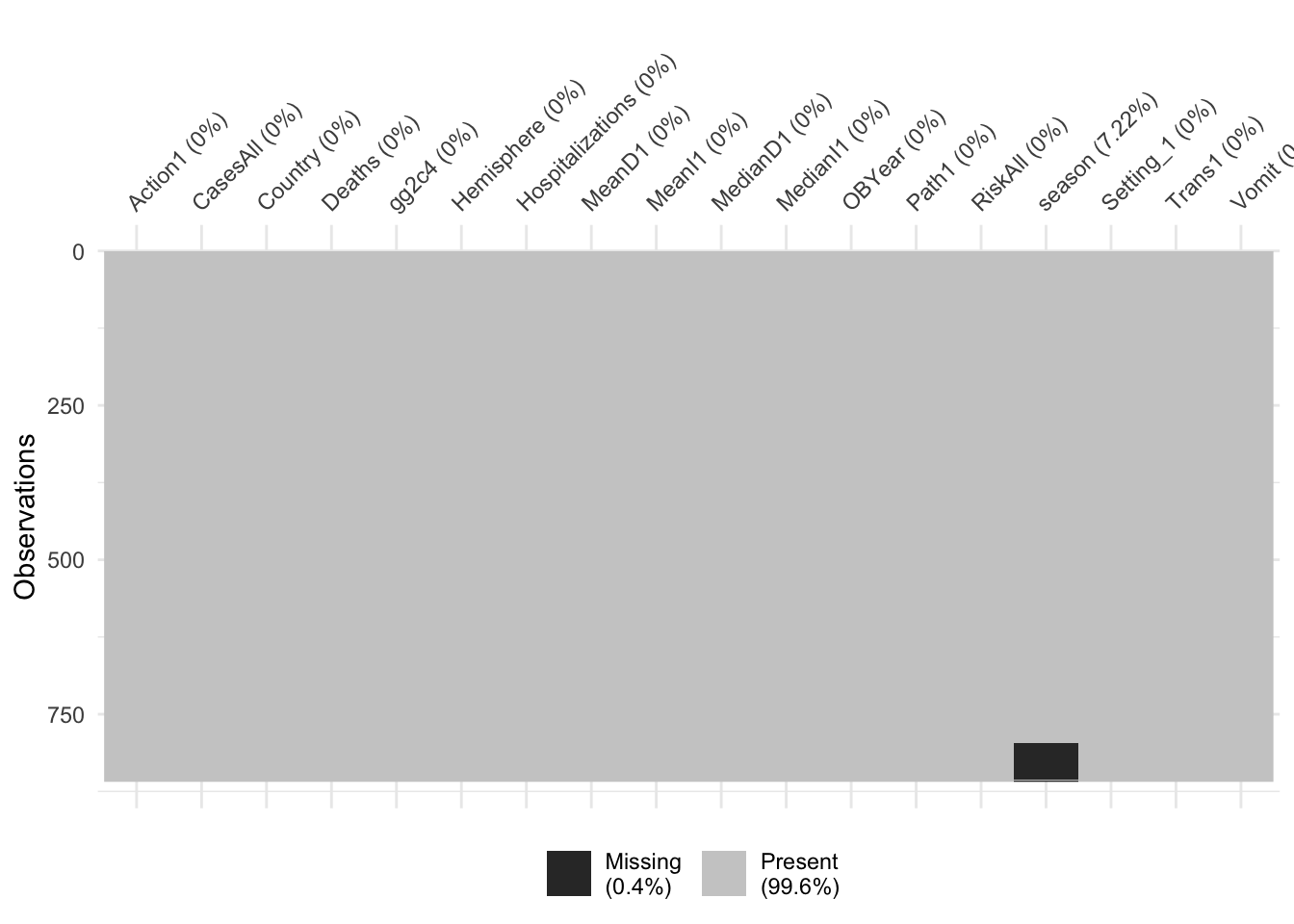
Let’s make sure everything has the right format (numeric/integer/factor). Adjust/recode variables as needed. You will likely find that as you convert OBYear to numeric, something doesn’t quite work. Take a look. Fix by removing the observation with the troublesome entry, then convert to numeric. Finally, remove the observations that have 0 as OByear - there are more than 1 now.
#write code that cleans OBYear, convert it to numeric. Remove observations with OBYear = 0.
#also convert any other variables as needed
str(d)## 'data.frame': 859 obs. of 18 variables:
## $ Action1 : Factor w/ 4 levels "No","Unknown",..: 3 3 3 3 3 3 3 3 3 4 ...
## $ CasesAll : num 15 65 27 4 15 6 40 10 116 45 ...
## $ Country : Factor w/ 22 levels "Australia","Austria",..: 12 22 17 17 17 17 17 17 17 22 ...
## $ Deaths : num 0 0 0 0 0 0 0 0 0 0 ...
## $ gg2c4 : Factor w/ 2 levels "No","Yes": 2 1 2 1 2 1 1 1 2 1 ...
## $ Hemisphere : Factor w/ 3 levels "Northern","Southern",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ Hospitalizations: num 0 0 0 0 0 0 0 0 5 10 ...
## $ MeanD1 : num 0 0 0 0 0 0 0 0 0 0 ...
## $ MeanI1 : num 0 0 0 0 0 0 0 0 0 0 ...
## $ MedianD1 : num 0 36 0 0 0 0 0 0 0 48 ...
## $ MedianI1 : num 0 37 0 0 0 0 0 0 0 31 ...
## $ OBYear : Factor w/ 23 levels "0","1983","1990",..: 11 10 19 19 19 19 19 19 17 5 ...
## $ Path1 : Factor w/ 4 levels "No","Unknown",..: 1 1 3 3 3 3 3 3 1 3 ...
## $ RiskAll : num 0 108 130 4 25 ...
## $ season : Factor w/ 4 levels "Fall","Spring",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ Setting_1 : Factor w/ 387 levels "0","2 communities near Apalachicola Bay",..: 119 30 37 309 37 351 37 309 199 1 ...
## $ Trans1 : Factor w/ 6 levels "Environmental",..: 5 2 2 2 2 2 2 2 5 2 ...
## $ Vomit : num 1 1 1 1 1 1 1 1 1 1 ...## Warning: NAs introduced by coercion
## 'data.frame': 853 obs. of 18 variables:
## $ Action1 : Factor w/ 4 levels "No","Unknown",..: 3 3 3 3 3 3 3 3 3 4 ...
## $ CasesAll : num 15 65 27 4 15 6 40 10 116 45 ...
## $ Country : Factor w/ 22 levels "Australia","Austria",..: 12 22 17 17 17 17 17 17 17 22 ...
## $ Deaths : num 0 0 0 0 0 0 0 0 0 0 ...
## $ gg2c4 : Factor w/ 2 levels "No","Yes": 2 1 2 1 2 1 1 1 2 1 ...
## $ Hemisphere : Factor w/ 3 levels "Northern","Southern",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ Hospitalizations: num 0 0 0 0 0 0 0 0 5 10 ...
## $ MeanD1 : num 0 0 0 0 0 0 0 0 0 0 ...
## $ MeanI1 : num 0 0 0 0 0 0 0 0 0 0 ...
## $ MedianD1 : num 0 36 0 0 0 0 0 0 0 48 ...
## $ MedianI1 : num 0 37 0 0 0 0 0 0 0 31 ...
## $ OBYear : num 1999 1998 2006 2006 2006 ...
## $ Path1 : Factor w/ 4 levels "No","Unknown",..: 1 1 3 3 3 3 3 3 1 3 ...
## $ RiskAll : num 0 108 130 4 25 ...
## $ season : Factor w/ 4 levels "Fall","Spring",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ Setting_1 : Factor w/ 387 levels "0","2 communities near Apalachicola Bay",..: 119 30 37 309 37 351 37 309 199 1 ...
## $ Trans1 : Factor w/ 6 levels "Environmental",..: 5 2 2 2 2 2 2 2 5 2 ...
## $ Vomit : Factor w/ 2 levels "0","1": 2 2 2 2 2 2 2 2 2 2 ...Next, we remove the Unspecified entry in Hemisphere and recode Action1 and Path1 as described in the Data Analysis script, i.e. from Unknown to Unspecified. Also do the same grouping into just Restaurant and Other with the Setting_1 variable. Again, remember that there are restaurant and Restaurant values, so you need to fix that too.
# write code that performs the actions described above
# at the end, use the droplevels() command to remove empty factor levels
#remove the Unspecified entry in Hemisphere:
unique(d$Hemisphere)## [1] Northern Southern Unspecified
## Levels: Northern Southern Unspecified## [1] Northern Southern
## Levels: Northern Southern## [1] "No" "Unknown" "Unspecified" "Yes"d$Action1 <- fct_collapse(d$Action1, Unspecified = c("Unknown", "Unspecified"), Yes = "Yes", No = "No")
levels(d$Path1)## [1] "No" "Unknown" "Unspecified" "Yes"d$Path1 <- fct_collapse(d$Path1, Unspecified = c("Unknown", "Unspecified"), Yes = "Yes", No = "No")
levels(d$Action1)## [1] "No" "Unspecified" "Yes"## [1] "No" "Unspecified" "Yes"#Group setting_1 into only two factors
d <- d %>%
mutate(Setting = ifelse(str_detect(d$Setting_1, "[R|r]est*")== TRUE, "Restaurant", "Other"))
d <- d %>%
select(-Setting_1)
d$Setting <- as.factor(d$Setting)
str(d$Setting)## Factor w/ 2 levels "Other","Restaurant": 1 1 1 2 1 2 1 2 1 1 ...Data visualization
Next, let’s create a few plots showing the outcome and the predictors. For the continuous predictors, I suggest scatter/box/violinplots with the outcome on the x-axis.
#write code that produces plots showing our outcome of interest on the x-axis and each numeric predictor on the y-axis.
#you can use the facet_wrap functionality in ggplot for it, or do it some other way.
d <- d[,c(5, 1:4, 6:18)]
d %>%
gather(c(CasesAll, Deaths, Hospitalizations, MeanD1, MeanI1, MedianD1, MedianI1, RiskAll, OBYear), key = "var", value = "value") %>%
ggplot(aes(x = gg2c4, y = value)) +
geom_violin() +
facet_wrap(~ var, scales = 'free')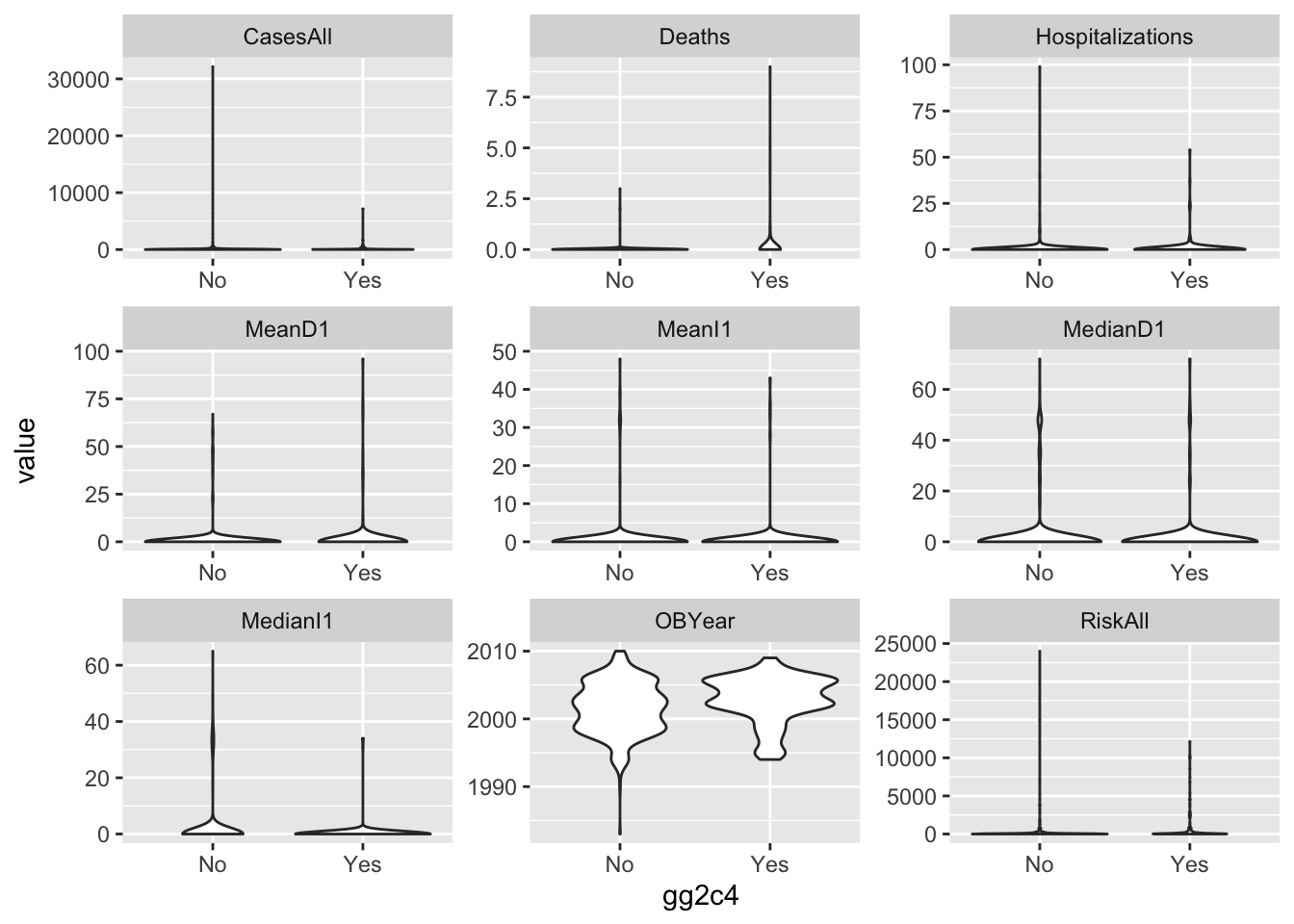
Things look ok, apart from the skew in the predictors we discussed previously.
Next, let’s create plots for the categorical variabless. You can use for instance geom_count for it, or some other representation. If you prefer lots of tables, that’s ok too.
#write code that produces plots or tables showing our outcome of interest and each categorical predictor.
d %>%
gather(c(Action1, Country, Hemisphere, Path1, season, Trans1, Vomit, Setting), key = "var", value = "value") %>%
ggplot(aes(x = gg2c4, y = value)) +
geom_count() +
facet_wrap(~ var, scales = 'free')## Warning: attributes are not identical across measure variables;
## they will be dropped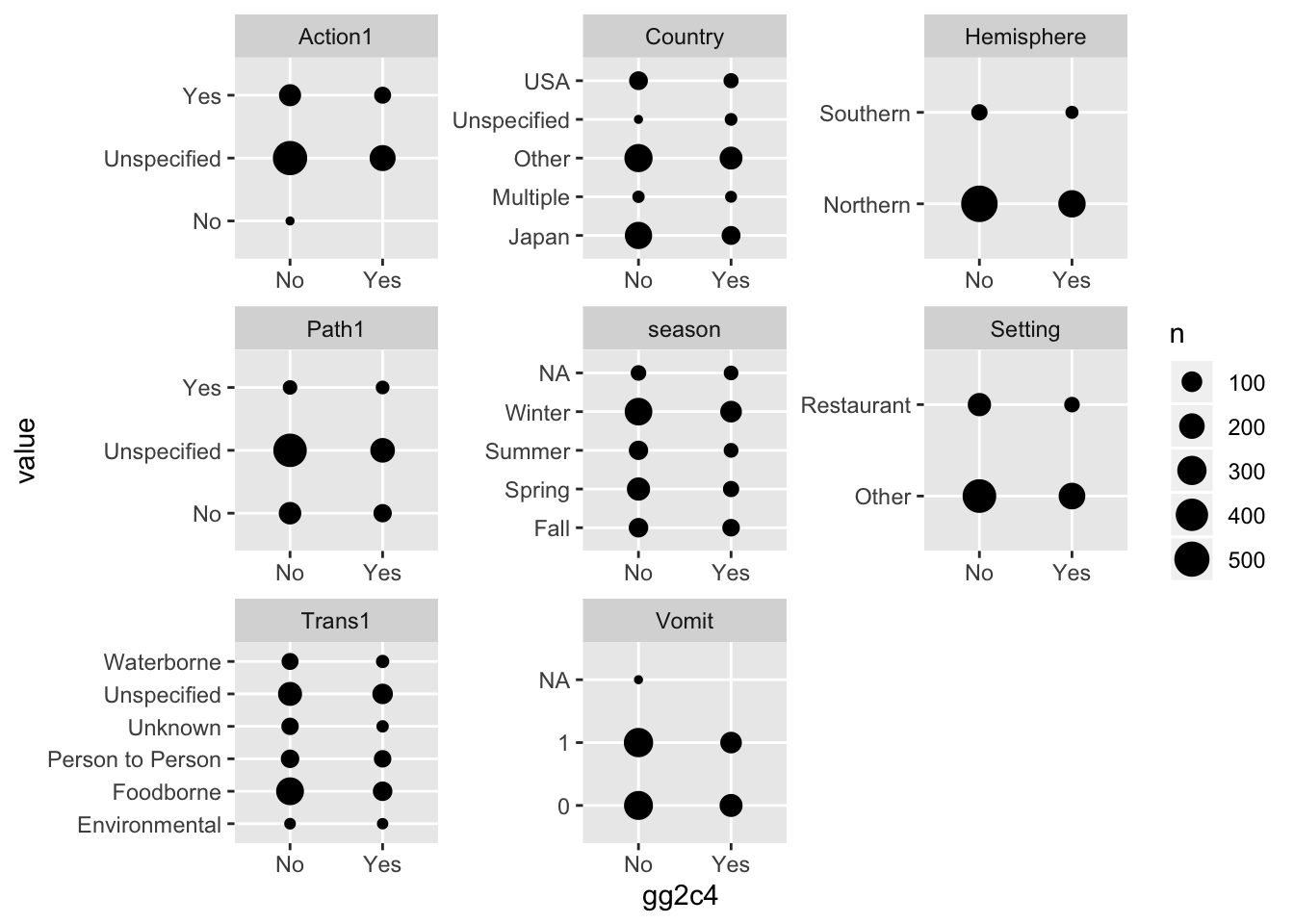
You should see from plots or tables that some of the categories are small, e.g. for Action1, the “No” category is very small. Very few entries for a given factor create problems during cross-validation (since we can’t have a level show up in the holdout if it wasn’t part of the fitting set). So let’s look at those factor variables a bit closer and fix as needed.
I didn’t initially get the results described. I initially interpreted the previous step where we dropped NAs to mean that we drop ALL NAs, not just the ones in the three categories.
##
## Northern Southern
## 799 53##
## No Unspecified Yes
## 197 615 40##
## Fall Spring Summer Winter
## 135 187 103 371##
## Other Restaurant
## 671 181##
## Environmental Foodborne Person to Person Unknown
## 11 339 119 61
## Unspecified Waterborne
## 261 61##
## No Unspecified Yes
## 1 679 172##
## Japan Multiple Other Unspecified USA
## 316 16 410 12 98## Factor w/ 4 levels "Fall","Spring",..: 1 1 1 1 1 1 1 1 1 1 ...## [1] "Fall" "Spring" "Summer" "Winter"You should see from your explorations above that there is only a single entry for No in Action1, and small entries for Multiple and Unspecified in Country and Environmental in Trans1. The single No should be fixed, the other somewhat small groupings might be ok. It depends on scientific rationale and method of analysis if you should modify/group those or not. We’ll do that.
Change things as follows: Remove the observation for which action is No, combine Countries into 3 groups Japan/USA/Other, and since I don’t even know what biologically the difference is between Environmental and Waterborne transmission (seems the same route to me based on my norovirus knowledge), we’ll move the Waterborne into the environmental. Finally, I noticed there is a blank category for season. That likely means it wasn’t stated in the paper. Let’s recode that as Unknown. Finally, re-order data such that the outcome is the first column and again remove empty factor levels. Then look at your resulting data frame.
#write code that does the actions described above
#Remove observation with "No" for action1...I don't have that observation. I think I dropped it when I dropped NAs.
d <- d %>%
filter(Action1 != "No")
#Combine "Countries into 3 groups":
levels(d$Country)## [1] "Japan" "Multiple" "Other" "Unspecified" "USA"## Warning: Unknown levels in `f`: Australia, Austria, Brazil, Ca da, Chi,
## Croatia, Denmark, France, Iraq, Israel, Italy, Netherlands, New Zealand,
## Norway, Scotland, Spain, UK## [1] "Japan" "Other" "USA"#Combine Environmental and Waterborne transmission --- I also moved Unknown and Unspecified into the same level of Unspecified
levels(d$Trans1)## [1] "Environmental" "Foodborne" "Person to Person"
## [4] "Unknown" "Unspecified" "Waterborne"d$Trans1 <- fct_collapse(d$Trans1, Environmental = c("Environmental", "Waterborne"), Unspecified = c("Unknown", "Unspecified"))
levels(d$Trans1)## [1] "Environmental" "Foodborne" "Person to Person"
## [4] "Unspecified"## [1] "Fall" "Spring" "Summer" "Winter"## [1] Fall Spring Summer Winter <NA>
## Levels: Fall Spring Summer Winter## [1] Fall Spring Summer Winter Unknown
## Levels: Fall Spring Summer Winter Unknown## [1] "Fall" "Spring" "Summer" "Winter" "Unknown"d <- droplevels(d)
#I still have on NA in vomit, so I'm going to drop that to get to the 850 observations
#Drop NAs in Vomit
d <- d %>%
filter(is.na(Vomit) == FALSE)
visdat::vis_dat(d)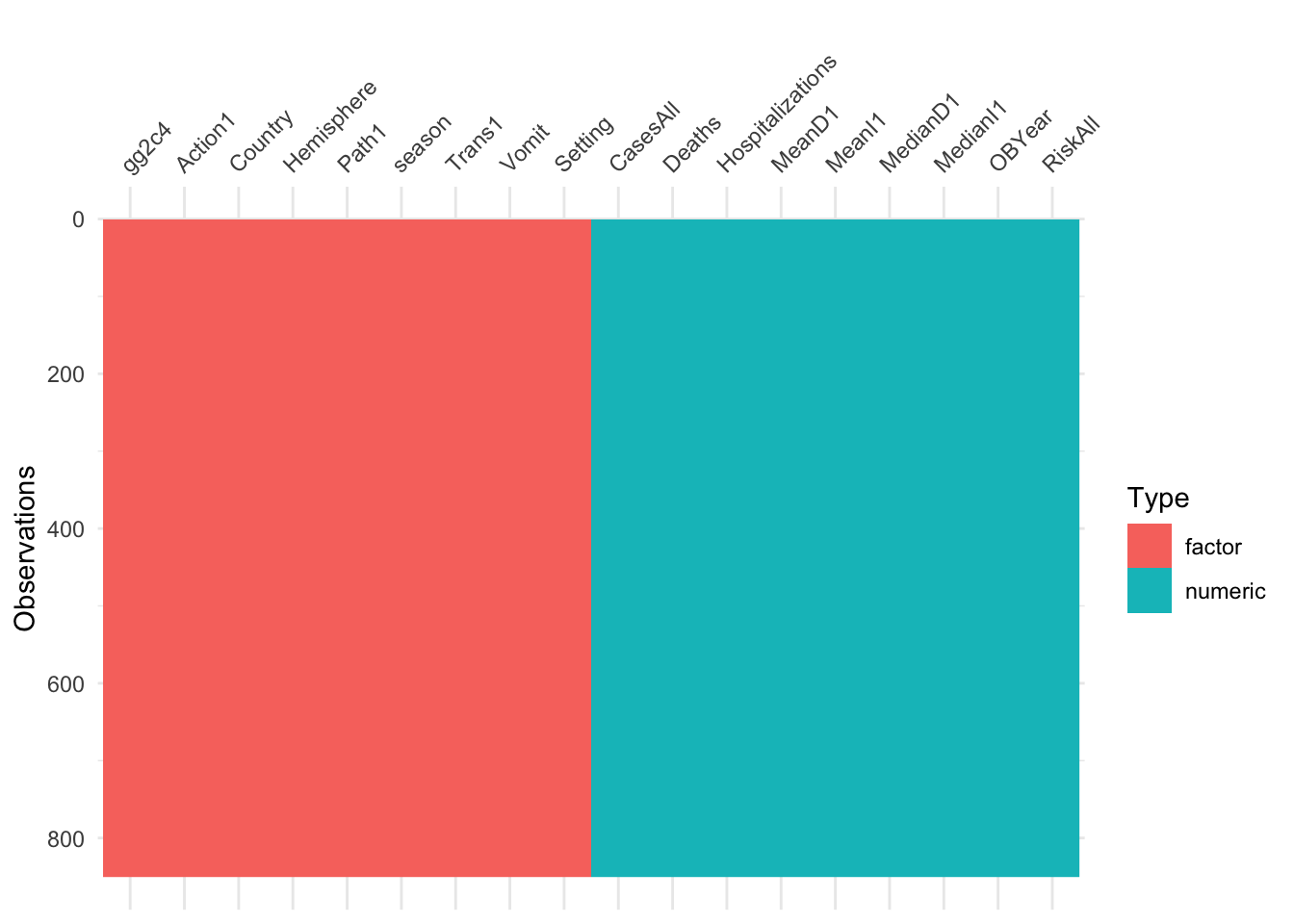
At this step, you should have a dataframe containing 850 observations, and 18 variables: 1 outcome, 9 numeric/integer predictors, and 8 factor variables. There should be no missing values. The outcome, gg2c4, should be in the 1st slot.
Data splitting
We could do data splitting again as we did in the previous exercise, to have a final test set. But since you saw how it works in the previous exercise, we skip it here. We use the full data to fit to our models. We’ll still use cross-validation to get a more honest estimate of model performance. For a real data analysis, the choice to keep some for a final test or not is based on your goals. If your focus is predictive performance, you should consider this split. If your focus is inference or exploratory analysis, you might want to skip this.
Model fitting
So I had planned to use caret exclusivley for this course. Last time I tried feature/subset selection with caret, I found it buggy and not too well documented. I had hoped this had improved since. Unfortunately, I was again not really able to get things to work. So even though I said we likely won’t use the mlr package, I decided that to be able to nicely practice feature/subset selection, we need to do so. It’s not a bad idea to get familiar with that package, at times caret can do things mlr can’t do and the reverse. So knowing how to use both is good. We’ll thus use mlr to do our model fitting in this exercise.
Parallelization
mlr allows you to run things in parallel by using multiple cores (caret does too). For instance, if you do 5x cross-validation 5x repeated, you essentially run a very similar piece of code 25 times. Normally, you would run one at a time. But if you have it on a machine with 25 cores, all those 25 could run at the same time, giving you a speed-up of 25 (or close to, there is usually some overhead related to doing things in parallel). This kind of parallel computing is sometimes called embarassingly parallel, because it’s so embarassingly simple to split the task into parallel streams.
Since doing the subset selection below starts getting slow, and because it’s a good topic to know about, we are going to use parallelization here. mlr uses the package parallelMap for this. All you need to do is specify the number of cores/processors you want to use and start the parallel system, and mlr then automatically does things in parallel if feasible.
#set the number of cores you want to use. Note that this is actually the number of 'logical processors', which is 2x the number of cores. On a windows machine, the number of cores/logical processors can be found in the task manager. You should only set it to what your computer has (or less). So if your computer has say 4 or 6 cores, you can set it to that, or some lower number. Setting it to a number higher than the cores your computer has doesn't further speed up things, in fact it slows things down.
ncpu=4;
#if you don't want to run things in parallel, or don't have multiple cores (unlikely nowadays),
#just comment out the line below.
parallelStartSocket(ncpu, show.info=FALSE) Setup
Some setup settings that are used in various code chunks below.
outcome <- d$gg2c4
outcomename = "gg2c4"
predictors <- d[,-1]
npred=ncol(predictors)
#set sampling method for performance evaluation
#here, we use 5-fold cross-validation, 5-times repeated
sampling_choice = makeResampleDesc("RepCV", reps = 5, folds = 5)A null model
To define a null model, we need to determine what performance measure we want to track. As mentioned in the course materials, there are different performance measures. Accuracy or misclassification error is simple, it just counts the number of times the model got it right/wrong. We’ll start with that one, and then try another one later. mlr allows for a lot of different performance measures for both categorical and continuous outcomes, see here and here.
For accuracy, the simplest null model always predicts the most frequent category. We can use that as baseline performance.
##
## No Yes
## 591 259#the null model always predicts "No" becuase this is the most frequent category of our expected outcome.
measureACC(d$gg2c4, "No")## [1] 0.6952941You should find that the null model has an accuracy of around 0.69.
Single predictor models
Now let’s consider single predictor models, i.e. we’ll fit the outcome to each predictor one at a time to get an idea of the importance of individual predictors. To evaluate our model performance, we will use cross-validation. Since our outcome is categorical, we’ll use a logistic model.
set.seed(1111) #makes each code block reproducible
#set learner/model. this corresponds to a logistic model.
#mlr calls different models different "learners"
learner_name = "classif.binomial";
mylearner = makeLearner(learner_name, predict.type = "prob")
# this will contain the results
unifmat=data.frame(variable = rep(0,npred), Accuracy = rep(0,npred))
# loop over each predictor, build simple dataset with just outcome and that predictor, fit it to a glm/logistic model
for (nn in 1:npred)
{
unidata = data.frame(gg2c4 = outcome, d[,nn+1] )
## Generate the task, i.e. define outcome and predictors to be fit
mytask = makeClassifTask(id='unianalysis', data = unidata, target = outcomename, positive = "Yes")
model = resample(mylearner, task = mytask, resampling = sampling_choice, show.info = FALSE, measures = acc )
unifmat[nn,1] = names(predictors)[nn]
unifmat[nn,2] = model$aggr
}
kable(unifmat)| variable | Accuracy |
|---|---|
| Action1 | 0.6952941 |
| CasesAll | 0.6941176 |
| Country | 0.6952941 |
| Deaths | 0.6976471 |
| Hemisphere | 0.6952941 |
| Hospitalizations | 0.6943529 |
| MeanD1 | 0.6952941 |
| MeanI1 | 0.6952941 |
| MedianD1 | 0.6952941 |
| MedianI1 | 0.6952941 |
| OBYear | 0.6950588 |
| Path1 | 0.6952941 |
| RiskAll | 0.6957647 |
| season | 0.6934118 |
| Trans1 | 0.6952941 |
| Vomit | 0.6952941 |
| Setting | 0.6952941 |
So looks like none of the single predictor models have a higher accuracy than the null. Maybe surprising. We’ll get back to that below.
Full model
Now let’s fit a full logistic model with all predictors.
set.seed(1111) #makes each code block reproducible
#do full model with Cross-Validation - to get an idea for the amount of over-fitting a full model does
mytask = makeClassifTask(id='fullanalysis', data = d, target = outcomename, positive = "Yes")
fullmodel = resample(mylearner, task = mytask, resampling = sampling_choice, show.info = FALSE, measures = acc )
ACC_fullmodel = fullmodel$aggr[1]
print(ACC_fullmodel)## acc.test.mean
## 0.7084706So a very small improvement over the simple models.
Now let’s do subset selection. The code below does it several ways. It does regular forward and backward selection and floating versions of those. It also uses a genetic algorithm for selection. See the mlr website here for details.
Also note that I included a kind of timer in the code, to see how long things take. That’s a good idea if you run bigger models. You first run a few iterations on maybe a few cores, then you can compute how long it would take if you doubled the iterations, or doubled the cores, etc. This prevents bad surprises of trying to quickly run a piece of code and waiting hours. You should always use short runs to make sure everything works in principle, and only at the end do the real, long “production” runs. Otherwise you might waste hours/days/weeks waiting for results only to realize that you made a basic mistake and you have to do it all over.
set.seed(1111)
tstart=proc.time(); #capture current CPU time for timing how long things take
#do 2 forms of forward and backward selection, just to compare
select_methods=c("sbs","sfbs","sfs","sffs")
resmat=data.frame(method = rep(0,4), Accuracy = rep(0,4), Model = rep(0,4))
ct=1;
for (select_method in select_methods) #loop over all stepwise selection methods
{
ctrl = makeFeatSelControlSequential(method = select_method)
print(sprintf('doing subset selection with method %s ',select_method))
sfeat_res = selectFeatures(learner = mylearner,
task = mytask,
resampling = sampling_choice,
control = ctrl,
show.info = FALSE,
measures = acc)
resmat[ct,1] = select_methods[ct]
resmat[ct,2] = sfeat_res$y
resmat[ct,3] = paste(as.vector(sfeat_res$x), collapse= ', ')
ct=ct+1;
}## [1] "doing subset selection with method sbs "
## [1] "doing subset selection with method sfbs "
## [1] "doing subset selection with method sfs "
## [1] "doing subset selection with method sffs "# do feature selection with genetic algorithm
maxit = 100 #number of iterations - should be large for 'production run'
ctrl_GA =makeFeatSelControlGA(maxit = maxit)
print(sprintf('doing subset selection with genetic algorithm'))## [1] "doing subset selection with genetic algorithm"sfeatga_res = selectFeatures(learner = mylearner,
task = mytask,
resampling = sampling_choice,
control = ctrl_GA,
show.info = FALSE,
measures = acc)
resmat[5,1] = "GA"
resmat[5,2] = sfeatga_res$y
resmat[5,3] = paste(as.vector(sfeatga_res$x), collapse= ', ')
runtime.minutes_SS=(proc.time()-tstart)[[3]]/60; #total time in minutes the optimization took
print(sprintf('subset selection took %f minutes',runtime.minutes_SS));## [1] "subset selection took 2.358467 minutes"| method | Accuracy | Model |
|---|---|---|
| sbs | 0.7261176 | Action1, Country, Deaths, Hemisphere, OBYear, RiskAll, season, Trans1, Vomit, Setting |
| sfbs | 0.7155294 | Action1, Country, Deaths, OBYear, season, Trans1, Setting |
| sfs | 0.6952941 | |
| sffs | 0.6952941 | |
| GA | 0.7263529 | Action1, Country, Deaths, Hemisphere, OBYear, Path1, RiskAll, season, Trans1, Vomit, Setting |
So we find that some of the sub-models perform somewhat better. Note that the different methods find different submodels and the forward selection method seems to fail (since none of the single-predictor models is better than the null, it stops there). Also note that the genetic algorithm was only allowed to run for a short time (the number if iterations is small). To get potentially better results, that should be increased to a larger number, e.g. 1000 or more. But this will take a longer time, unless you have many cores you can use when you parallelize.
Different performance measures
So far, we found that some of the sub-models provide a minor improvement over the simple null or single-predictor models or the full model. However, the improvement is not much.
We could try tweaking further, e.g. by pre-processing the predictors (which is a good idea to try, but we won’t do here) or testing a different model (which we’ll do below).
For now, I want to discuss performance measure a bit more. The problem is that logistic regression, as well as many (though not all) algorithms that are used for classification (predicting categorical outcomes) return probabilities for an outcome to belong to a certain category. Those are then turned into Yes/No predictions (in the case with 2 outcomes like we have here), based on some cut-off. By default, a probability value of 0.5 is chosen. If the model predicts that there is a 0.5 or greater probability of the outcome being “Yes”, it is scored as such in the prediction, otherwise as no. However, this 0.5 threshold is not always good. It could be that we might get a much better model if we use another threshold. There is a technique that scans over different thresholds and evaluates model performance for each threshold. This is generally called receiver operating curve. If this concept is new to you, check out this article on Wikipedia or this tutorial on the mlr website.
Using this approach, a model is evaluated based on the Area under the curve (AUC), with an AUC=0.5 meaning a model is not better than chance, and AUC=1 meaning a perfect model. Let’s re-do the analysis above, but replace accuracy with AUC.
Model performance with AUC
#write code that computes AUC for a null model
#the null model always predicts "No"
#the auc function in the pROC package is useful
#or you can use any other package/function you want to use to compute AUC/ROC
library(pROC)## Type 'citation("pROC")' for a citation.##
## Attaching package: 'pROC'## The following objects are masked from 'package:stats':
##
## cov, smooth, var## Setting levels: control = No, case = Yes## Setting direction: controls < cases## Area under the curve: 0.5You should find that the null model has an AUC of 0.5, as expected for a “no information” model.
Now we run the single-predictor models again.
#copy and paste the code from above for single predictor fits, but now switch to AUC instead of accuracy.
set.seed(1111) #makes each code block reproducible
#set learner/model. this corresponds to a logistic model.
#mlr calls different models different "learners"
learner_name = "classif.binomial";
mylearner = makeLearner(learner_name, predict.type = "prob")
# this will contain the results
unifmat=data.frame(variable = rep(0,npred), Accuracy = rep(0,npred))
# loop over each predictor, build simple dataset with just outcome and that predictor, fit it to a glm/logistic model
for (nn in 1:npred){
unidata = data.frame(gg2c4 = outcome, d[,nn+1] )
## Generate the task, i.e. define outcome and predictors to be fit
mytask = makeClassifTask(id='unianalysis', data = unidata, target = outcomename, positive = "Yes")
model = resample(mylearner, task = mytask, resampling = sampling_choice, show.info = FALSE, measures = mlr::auc )
unifmat[nn,1] = names(predictors)[nn]
unifmat[nn,2] = model$aggr
}
kable(unifmat)| variable | Accuracy |
|---|---|
| Action1 | 0.5154141 |
| CasesAll | 0.4649312 |
| Country | 0.5782066 |
| Deaths | 0.5160717 |
| Hemisphere | 0.5090307 |
| Hospitalizations | 0.5011048 |
| MeanD1 | 0.4952809 |
| MeanI1 | 0.4995563 |
| MedianD1 | 0.5171011 |
| MedianI1 | 0.5285258 |
| OBYear | 0.6015035 |
| Path1 | 0.5263330 |
| RiskAll | 0.5715641 |
| season | 0.5879504 |
| Trans1 | 0.5769839 |
| Vomit | 0.5297235 |
| Setting | 0.5641744 |
Looks like there are a few single-predictor models with better performance than the null model.
Now let’s again fit a full model with all predictors.
#copy and paste the code from above for the full model fit, but now switch to AUC instead of accuracy.
set.seed(1111) #makes each code block reproducible
#do full model with Cross-Validation - to get an idea for the amount of over-fitting a full model does
mytask = makeClassifTask(id='fullanalysis', data = d, target = outcomename, positive = "Yes")
fullmodel = resample(mylearner, task = mytask, resampling = sampling_choice, show.info = FALSE, measures = mlr::auc )
AUC_fullmodel = fullmodel$aggr[1]
print(AUC_fullmodel)## auc.test.mean
## 0.6752942This is better than any single-predictor models. Let’s see if a sub-model can do even better.
#copy and paste the code from above for the subset selection, but now switch to AUC instead of accuracy.
set.seed(1111)
tstart=proc.time(); #capture current CPU time for timing how long things take
#do 2 forms of forward and backward selection, just to compare
select_methods=c("sbs","sfbs","sfs","sffs")
resmat=data.frame(method = rep(0,4), Accuracy = rep(0,4), Model = rep(0,4))
ct=1;
for (select_method in select_methods) #loop over all stepwise selection methods
{
ctrl = makeFeatSelControlSequential(method = select_method)
print(sprintf('doing subset selection with method %s ',select_method))
sfeat_res = selectFeatures(learner = mylearner,
task = mytask,
resampling = sampling_choice,
control = ctrl,
show.info = FALSE,
measures = mlr::auc)
resmat[ct,1] = select_methods[ct]
resmat[ct,2] = sfeat_res$y
resmat[ct,3] = paste(as.vector(sfeat_res$x), collapse= ', ')
ct=ct+1;
}## [1] "doing subset selection with method sbs "
## [1] "doing subset selection with method sfbs "
## [1] "doing subset selection with method sfs "
## [1] "doing subset selection with method sffs "# do feature selection with genetic algorithm
maxit = 100 #number of iterations - should be large for 'production run'
ctrl_GA =makeFeatSelControlGA(maxit = maxit)
print(sprintf('doing subset selection with genetic algorithm'))## [1] "doing subset selection with genetic algorithm"sfeatga_res = selectFeatures(learner = mylearner,
task = mytask,
resampling = sampling_choice,
control = ctrl_GA,
show.info = FALSE,
measures = mlr::auc)
resmat[5,1] = "GA"
resmat[5,2] = sfeatga_res$y
resmat[5,3] = paste(as.vector(sfeatga_res$x), collapse= ', ')
runtime.minutes_SS=(proc.time()-tstart)[[3]]/60; #total time in minutes the optimization took
print(sprintf('subset selection took %f minutes',runtime.minutes_SS));## [1] "subset selection took 2.532800 minutes"| method | Accuracy | Model |
|---|---|---|
| sbs | 0.6856703 | Action1, Country, Deaths, MedianI1, OBYear, RiskAll, season, Setting |
| sfbs | 0.6782245 | Action1, Country, Deaths, MedianI1, OBYear, season, Setting |
| sfs | 0.6555854 | OBYear, season, Setting |
| sffs | 0.6638263 | Country, OBYear, season, Setting |
| GA | 0.6839415 | Action1, Country, Deaths, MedianI1, OBYear, RiskAll, season, Setting |
Looks like we get some sub-models that are slightly better than the full model, at least as evaluated using the (cross-validated) AUC measure.
More on ROC/AUC
While this is a common measure and useful to evaluate how models perform at different cut-off levels, one needs to keep in mind that this doesn’t really measure the performance of a single model, but instead the combined performance of all models with different cut-offs. In practice, if we want to use a model, we have to pick one cut-off. For that purpose, one can look at the whole ROC curve and one then usually chooses the model in the “top-left” corner of the curve, which gives the best overall performance with a good balance between FP and TP. Let’s plot that ROC curve for the model found by the GA.
set.seed(1111) #makes each code block reproducible
d2 <- d %>% dplyr::select(gg2c4, sfeatga_res$x )
mytask = makeClassifTask(id='rocanalysis', data = d2, target = outcomename, positive = "Yes")
log_mod = train(mylearner, mytask)
log_pred = predict(log_mod, task = mytask)
df = generateThreshVsPerfData(list(logistic = log_pred), measures = list(fpr, tpr))
plotROCCurves(df)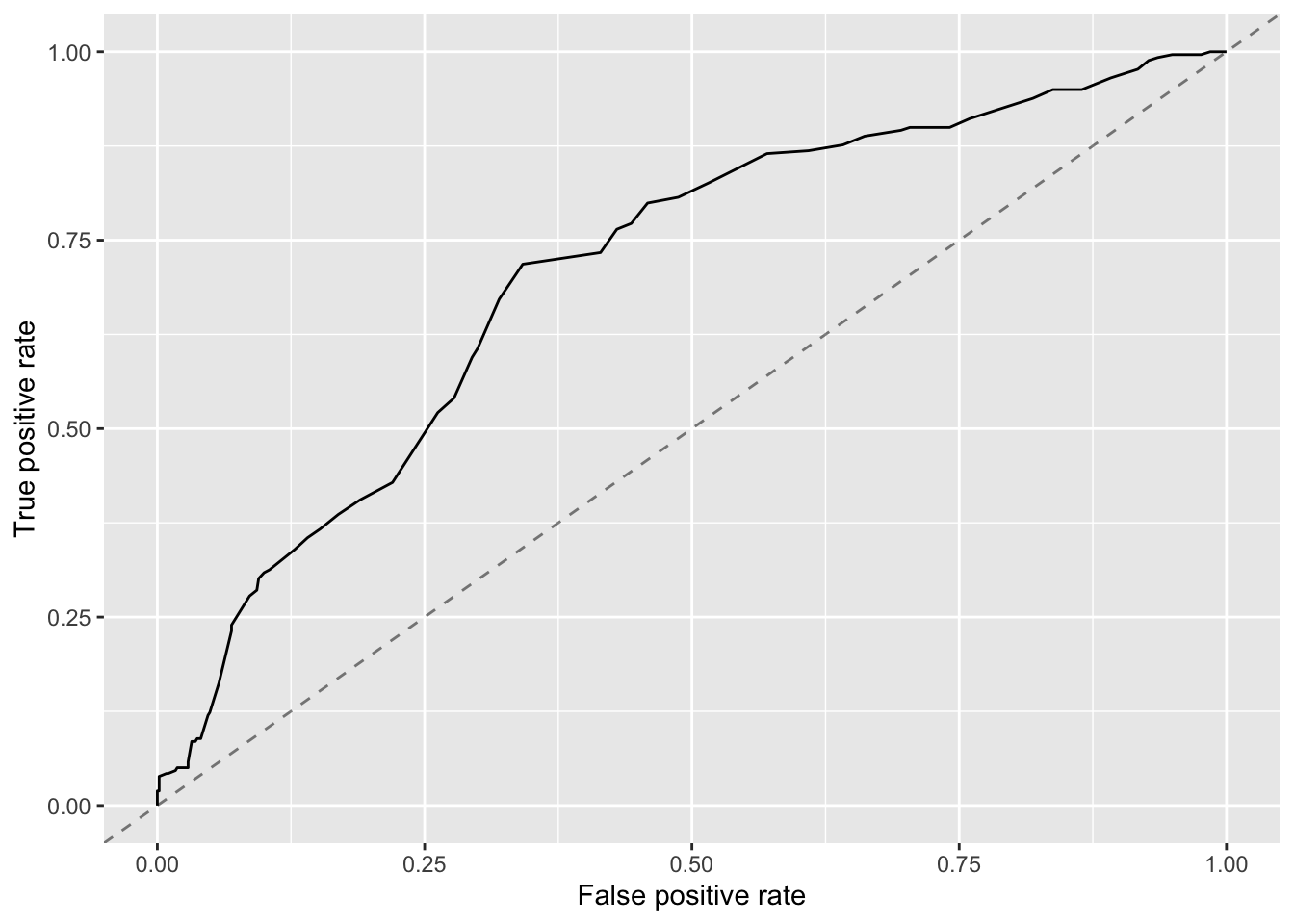
Based on this plot, a FP of around 0.5 an TP of around 0.75 seem to produce a good model. Digging into the df object, you can find the raw data underlying the curve in df$data and will find
## fpr tpr threshold
## 29 0.4433164 0.7722008 0.2828283
## 30 0.4297800 0.7644788 0.2929293
## 31 0.4145516 0.7335907 0.3030303This means for this model, if we were to use it we might want to set a threshold of around 0.3, i.e. everything above that probability would be predicted as positive/yes.
Trying a different model
Let’s see if we can find another model that might perform even better. Let’s look at a Linear Discriminant Analysis (LDA) model. See e.g. chapter 4 of ISLR for more on that model. We again consider AUC as our measure. The null-model performance is the same, we need to re-do the remainder.
Let’s re-run the single model, followed by the full model and subset selection.
#copy and paste the code from above for single predictor fits. Switch the learner from a the logistic model to a LDA model. Check the mlr website to figure out the name for that learner. (see 'integrated learner' section)
set.seed(1111) #makes each code block reproducible
#set learner/model. this corresponds to a logistic model.
#mlr calls different models different "learners"
learner_name = "classif.lda";
mylearner = makeLearner(learner_name, predict.type = "prob")
# this will contain the results
unifmat=data.frame(variable = rep(0,npred), Accuracy = rep(0,npred))
# loop over each predictor, build simple dataset with just outcome and that predictor, fit it to a LDA model
for (nn in 1:npred)
{
unidata = data.frame(gg2c4 = outcome, d[,nn+1] )
## Generate the task, i.e. define outcome and predictors to be fit
mytask = makeClassifTask(id='unianalysis', data = unidata, target = outcomename, positive = "Yes")
model = resample(mylearner, task = mytask, resampling = sampling_choice, show.info = FALSE, measures = mlr::auc )
unifmat[nn,1] = names(predictors)[nn]
unifmat[nn,2] = model$aggr
}
kable(unifmat)| variable | Accuracy |
|---|---|
| Action1 | 0.5154141 |
| CasesAll | 0.4649312 |
| Country | 0.5782066 |
| Deaths | 0.5160717 |
| Hemisphere | 0.5090307 |
| Hospitalizations | 0.5011048 |
| MeanD1 | 0.4952809 |
| MeanI1 | 0.4995563 |
| MedianD1 | 0.5171011 |
| MedianI1 | 0.5285434 |
| OBYear | 0.6015035 |
| Path1 | 0.5263330 |
| RiskAll | 0.5715641 |
| season | 0.5879504 |
| Trans1 | 0.5769839 |
| Vomit | 0.5297235 |
| Setting | 0.5641744 |
#copy and paste the code from above for the full model fit, but now for LDA. Since you already switched the learner/model above, no further adjustment should be needed
set.seed(1111) #makes each code block reproducible
#do full model with Cross-Validation - to get an idea for the amount of over-fitting a full model does
mytask = makeClassifTask(id='fullanalysis', data = d, target = outcomename, positive = "Yes")
fullmodel = resample(mylearner, task = mytask, resampling = sampling_choice, show.info = FALSE, measures = mlr::auc )
AUC_fullmodel = fullmodel$aggr[1]
print(AUC_fullmodel)## auc.test.mean
## 0.6750281#copy and paste the code from above for subset selection, now for LDA. Since you already switched the learner/model above, no further adjustment should be needed
set.seed(1111)
tstart=proc.time(); #capture current CPU time for timing how long things take
#do 2 forms of forward and backward selection, just to compare
select_methods=c("sbs","sfbs","sfs","sffs")
resmat=data.frame(method = rep(0,4), Accuracy = rep(0,4), Model = rep(0,4))
ct=1;
for (select_method in select_methods) #loop over all stepwise selection methods
{
ctrl = makeFeatSelControlSequential(method = select_method)
print(sprintf('doing subset selection with method %s ',select_method))
sfeat_res = selectFeatures(learner = mylearner,
task = mytask,
resampling = sampling_choice,
control = ctrl,
show.info = FALSE,
measures = mlr::auc)
resmat[ct,1] = select_methods[ct]
resmat[ct,2] = sfeat_res$y
resmat[ct,3] = paste(as.vector(sfeat_res$x), collapse= ', ')
ct=ct+1;
}## [1] "doing subset selection with method sbs "
## [1] "doing subset selection with method sfbs "
## [1] "doing subset selection with method sfs "
## [1] "doing subset selection with method sffs "# do feature selection with genetic algorithm
maxit = 100 #number of iterations - should be large for 'production run'
ctrl_GA =makeFeatSelControlGA(maxit = maxit)
print(sprintf('doing subset selection with genetic algorithm'))## [1] "doing subset selection with genetic algorithm"sfeatga_res = selectFeatures(learner = mylearner,
task = mytask,
resampling = sampling_choice,
control = ctrl_GA,
show.info = FALSE,
measures = mlr::auc)
resmat[5,1] = "GA"
resmat[5,2] = sfeatga_res$y
resmat[5,3] = paste(as.vector(sfeatga_res$x), collapse= ', ')
runtime.minutes_SS=(proc.time()-tstart)[[3]]/60; #total time in minutes the optimization took
print(sprintf('subset selection took %f minutes',runtime.minutes_SS));## [1] "subset selection took 2.189400 minutes"| method | Accuracy | Model |
|---|---|---|
| sbs | 0.6855919 | Action1, Country, Deaths, MedianI1, OBYear, RiskAll, season, Setting |
| sfbs | 0.6769966 | Action1, Country, MedianI1, OBYear, RiskAll, season, Setting |
| sfs | 0.6566321 | OBYear, season, Setting |
| sffs | 0.6654399 | Country, OBYear, season, Setting |
| GA | 0.6834578 | Action1, Country, Deaths, MedianI1, OBYear, RiskAll, season, Setting |
It Looks like we again get some sub-models that are slightly better than the full model, at least as evaluated using the (cross-validated) AUC measure. There seems to be a bit, but not much difference in performance to the logistic model. We can take the GA model again (because it’s conveniently at the end, even if it’s not the best) and look at its ROC and compare the curves for the LDA and logistic models.
#copy the code from roc-plot above and re-do train/predict but now save it as lda_mod and lda_pred
#then use generateThreshVsPerfData() with both lda_pred and log_pred (computed above) to create a structure that contains
#best model curves for both logistic and LDA, then plot the curves.
set.seed(1111) #makes each code block reproducible
d2 <- d %>% dplyr::select(gg2c4, sfeatga_res$x )
mytask = makeClassifTask(id='rocanalysis', data = d2, target = outcomename, positive = "Yes")
lda_mod = train(mylearner, mytask)
lda_pred = predict(lda_mod, task = mytask)
df = generateThreshVsPerfData(list(logistic = log_pred, lda = lda_pred), measures = list(fpr, tpr))
plotROCCurves(df)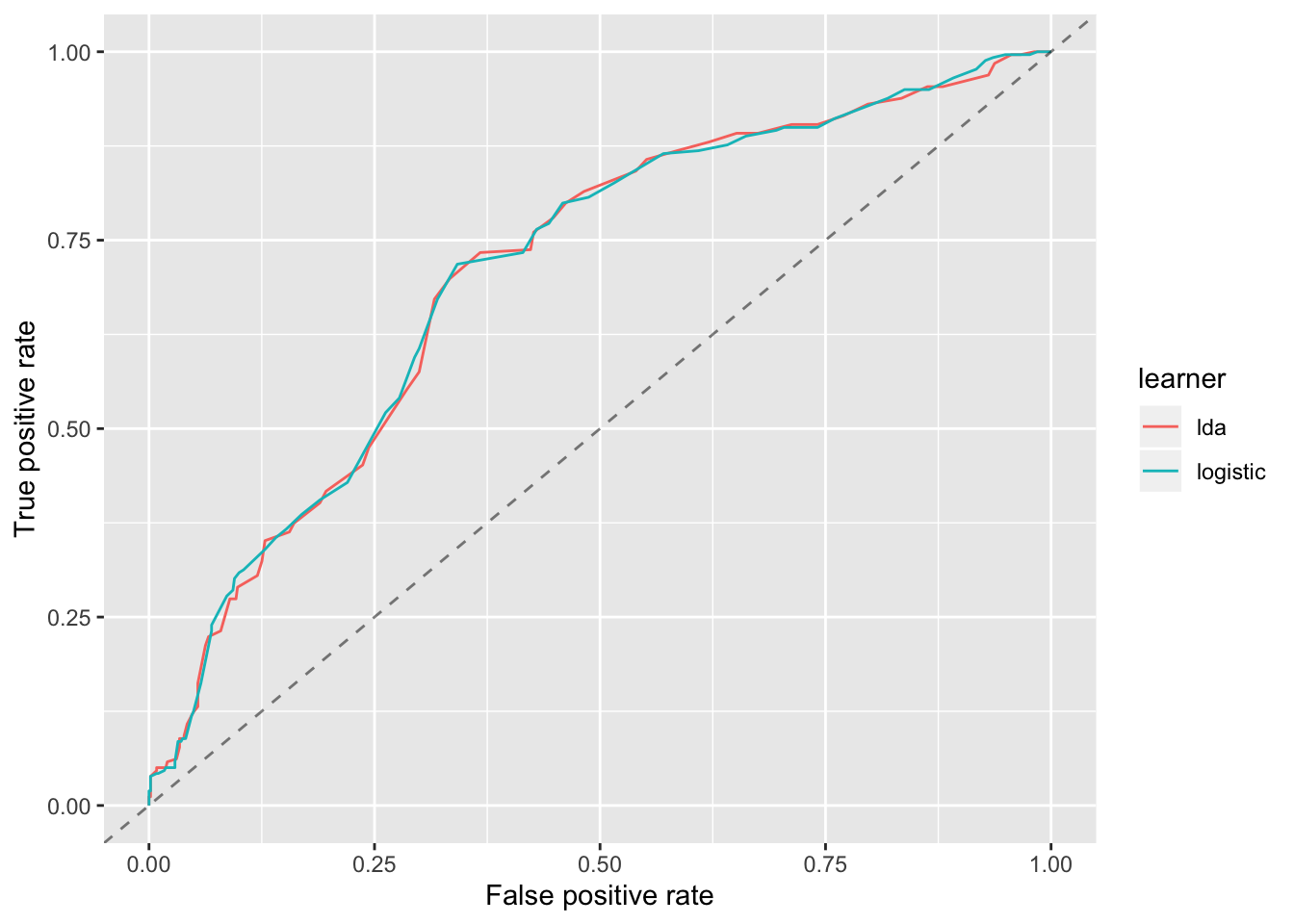
You should see from the plot that the LDA model performs very similar to the Logistic model.
Wrapping up
Based on the above, we could choose a model simply by best performance. However, we likely also still want to look at model prediction uncertainty and do some residual plots and other diagnostics for our chosen model before we finalize our choice. As was the case for caret, mlr also comes with lots of functions that make these - and many other - tasks easier. We’ll leave it at this for now, and might revisit some of those topics in further exercises.
Also, none of the models here are that great. We might want to think more about our initial premise, i.e. looking for associations between virus strain type and other variables and what the scientific rationale is for expecting variations. Here, we just ran the model and looked what we might find. That approach, sometimes called data exploration or data mining or - less charitable fishing expedition is ok, but we need to be careful how we interpret and use the results. Going in with a clear hypothesis is usually better.
A few more comments
Things are getting a bit slow now, despite the multiple cores we need minutes to run things. Also, code chunks get larger. At this point, it might be worth considering a structure whereby most of the code lives in one or several well documented R scripts, which can be run independently. Those R scripts should save their results, and those results are then loaded here. The advantage is that if one wants to make changes to a small part of the analysis, one can modify and run just that part and update the whole document by re-knitting without having to run all code. For any big/serious analysis, I suggest such a setup that splits R code from RMarkdown files, at least for the computationally intensive parts.